Geb + Jenkins(Geb実行時のキャプチャをJenkinsのテストケースに紐付ける)
TwitterとかFacebookのSNS疲れが著しいikikkoです。こんばんは。
最近久しぶりにGroovyを触ったので、生存確認の意味も込めてブログ書いておきます。
概要
Seleniumテストとかだと、実行時の画面のキャプチャを取っておきたいこともありますよね。で、せっかくキャプチャをとったはいいものの、そのキャプチャがどのテストに付随するものかがぱっと見分からないと、無駄な時間を過ごしてしまいます。
Jenkins上でテストを実行する前提として、Jenkinsのテストケースを表示する画面にそのテストケースで出力されたキャプチャが一緒に表示されると便利そうですよね。ということで、そんな設定をした画面を↓にお見せします。この画面を出すことが、今回のブログエントリの目標。
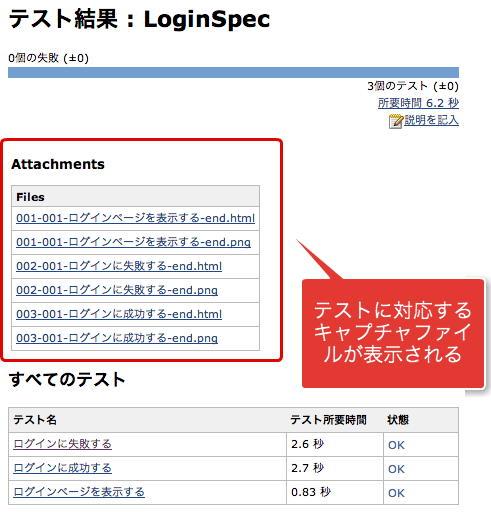
Jenkinsでテストケースとファイルの紐付
Junit Attachements Pluginを使えば、テストケースに任意のファイルを紐付けることができます。
紐付方法は2通りあります。
- テスト結果ファイル名に合わせてディレクトリを作成し、その中に紐付けるファイルを置く
- 標準出力/エラー出力に、ファイルのパスを出力する
- "[[ATTACHMENT|/absolute/path/to/some/file]]"という形式で出力
まあどっちでもいいんですが、後者の方が若干楽なのかな。
Gebでキャプチャ出力
Selenium(WebDriver)のGroovyラッパーにGebというものがあります。で、GebのSeleniumGebReportingSpecを使えば、各テストが終了するときにキャプチャを自動で出力することができます。今回は、これを使ってみました。
GebやGebReportingSpecの詳細については、Slideshareの資料とか、適当にぐぐるとかしてみてください。
Geb + Jenkins
ということで、Gebテスト実行時にキャプチャファイルのパスを出力するようにします。
ScreenshotAndPageSourceReporterがキャプチャ出力用のクラスで、この中のgetFileメソッドで出力用のキャプチャファイルを用意しているので、このメソッドをフックしてファイルパスを出力するようにします。GebConfig.groovyらへんに仕込んでおけばいいでしょう。この設定を仕込んだGebテストをJenkins上で実行すれば、冒頭であげたスクリーンショットのようにテストケースとキャプチャを同じ画面に表示できます。
reporter = new ScreenshotAndPageSourceReporter() { @Override protected getFile(File dir, String name, String extension) { def file = super.getFile(dir, name, extension) println "[[ATTACHMENT|${file.absolutePath}]]" file } }
ちなみに、GebConfig.groovyとは↓のようなもの。
Geb の共通設定を書いておくファイルの位置づけでしょうか。デフォルトパッケージに配置するということなので、src/test/resources の直下に GebConfig.groovy を実装します。
http://hideoku.hatenablog.jp/entry/20121029/1357389342
以上、2013年最初のブログでした。それではみなさん良いお年を!
HTTPアクセスを記録/再生してテスト時に使える、Betamaxを試してみたよ
「初夢が別の人と結婚する夢だった」と妻に話したら、「私も別の人と結婚してる夢を見て、子供も産まれてた」と返されて負けた気がしたikikkoです。あけましておめでとうございます。今年もよろしくお願いします。

概要
Betamax - Record / playback testing proxyとは・・・うまく説明できる気がしないので、丸ごと引用してきます。
BetamaxはWebへのアクセスを記録して再生することのできるrecord/playback proxy です。
最 近 の ア プ リ ケ ー シ ョ ン は Twitter や Facebook な ど 外 部 のWebAPIと連携するものが多くなってきていますが、Betamaxを利用すると実際にWebAPI やWebサイトへのアクセスを行わずにアプリケーションのテストを行うことができます。
Betamax はHTTP リクエスト・レスポンスのペアを、HTTP リクエストの内容をキーとして「tape」というテキストファイル(YAML) に記録します。テストケースに対してtapeを指定してやることで、既に記録済みのHTTP リクエストに対してはtape の内容が再生されます。未記録のHTTPリクエストであれば、実際に得られたレスポンスをキャプチャしてtape に記録します。
http://grails.jp/g_mag_jp/file/gmagazine_4.pdf
Groovyカテゴリに入れてますが、JUnitをはじめとしたJavaオンリーでも多分使うことができます(未検証)。
もうちょっとちゃんとした説明は、下記を参考にしてください(説明されている内容はどちらも大体同じです)。
メリット
いくつか参考資料中でも述べられていますが、外部にアクセスにいかないので下記のようなメリットがあります。
- オフラインでテスト実行できる
- スローテスト問題を解決できる
- (ネットワークや接続先での障害といった)外部環境の影響を受けにくい
- 更新系APIでの副作用問題が起きない
また、通信データを加工できるので
- レアケースを簡単に再現できる
- (認証情報などの)共有するべきでない個人情報を除去した上で、データを共有できる
というのもあげられるでしょう。
外部APIを使ったテストには、ダミーのモックを使うという選択肢もあります。ただ、Betamaxでは実際の通信データを再利用するので、まるごとモックを用意するよりは信頼できるデータといえるでしょう。
サンプル
サンプルでは、Cacoo APIを使っています。具体的には、図の新規作成/コメントの追加をCacoo API経由で行い、そのレスポンスから最新のコメントを取得するものです。Cacoo APIを含んだコードでも、毎回外部(Cacoo)に接続しに行かずにテストします*1。
サンプルコードは、Githubの下記の場所に置いています。Gradleでプロジェクトを作成しておりGradle Wrapperも用意しているので、cloneして"./gradlew test"と入力すればサンプルを実行することができます(Groovy環境も必要ありません)。テスト実行後、"build/reports/tests/index.html"で実行結果や出力を確認できます。
解説
メインのコードは以下です。
Betamaxの設定は大きくわけて、下記の2点です。
- @RuleにRecorderを設定する
- 各テストケースに@Betamaxを指定する
まず、RuleにRecorderを設定します。これは、単純に宣言するだけで十分です。
// Betamaxを使用して、通信内容をtapeに記録/読込できるようにする @Rule Recorder recorder = new Recorder()
@Betamaxでは、tapeの保存先を指定します。また、tapeから読み込むときの判定条件を「リクエストの(ホスト名+パス)が一致したとき」というように変更しています。デフォルトだとURI一致なのですが、今回はAPI Keyをクエリーストリングに含むのでURIが変わる可能性があったので、このようにしています。
// 保存先のtape名を指定, ホスト名/パスが一致した場合はtapeから読み込む(クエリは判定対象外) @Betamax(tape="create diagram", match=[ MatchRule.host, MatchRule.path ]) def "図の新規作成"() { ... }
tapeの記録
通信内容をtapeに記録するために、初回はHTTP通信が発生します。記録された通信内容は、YAML形式で保存されます。以下のファイルが、tape内容です。
- 図の新規作成
- コメントの追加
Cacoo APIを使う場合はAPI Keyが必要ですし、記録されたtapeにもAPI Keyも合わせて記録されています。ですが、push前に上記のtapeを直接編集して、API Keyの情報を除去しました。このように、一度tapeを作成してから、都合がいいようにデータを改ざんできるのもメリットの一つです。
tapeの再生
2回目以降は、作成されたtapeを元に通信が再生されます。以降はネットワークにつながっている必要がありません。また、API Keyを設定しておく必要もありません。
pushをしたものはすでにtapeの記録を行った状態なので、再生から実行することができます。
問題点・注意事項
HTTPSをサポートしていない
一番大きいのはHTTPSをまだサポートしていないということ。Issueとしてあがっているので認識はしていると思うのですが、いつサポートされるのかは分かりません。
これサポートされないと、多分厳しいよな・・・
HttpClientを使う場合は、Proxyの設定が必要
Betamaxでは、実行時にJavaのProxy設定をいじってBetamaxが起動しているサーバ(デフォルトではlocalhost, 5555)に向けます。ただ、HttpClientのデフォルト設定では、JavaのProxyの設定を参照しないようです。HttpClient(や内部でBetamaxを使っているHttpBuilder)でもBetamaxを使うために、ちょっと設定を追加する必要があります。サンプルコードではHttpBuilderを使っているので、それ用の設定も追加しています。
詳しくは、下記を参照してください。
公式サイトのドキュメントとリリース版のモジュールが一致していない
これにしばらくハマりました。ドイヒーですよね。
公式サイトにまだリリースされていない機能も書かれています。具体的には、betamax.propertiesというプロパティファイルでいくつか設定を変更できるのですが、これのignoreHosts/ignoreLocalhostが現在リリースバージョンの1.0には含まれていません。
他にもあるかもしれないので、注意しましょう。
どうでもいいですが、テニスの王子様って面白いですよね (・∀・)
Groovy Eclipse Pluginのあれこれ
この記事は、G* Advent Calendar 8日目の記事です。

最近Groovyを一番書いているエディタは、Jenkinsのスクリプトコンソールなikikkoです、こんにちは。Groovyはあまりコアな使い方はしていないので、ライトな記事でいかせていただきます。ということで、GroovyのEclipseプラグインについて。
Eclipseプラグイン
Groovy用のEclipseプラグイン、Groovy - Eclipse Pluginです。主な機能はこんな感じ。公式サイトから転載して、適当な日本語に訳してます。
- シンタックスハイライト
- 型推論
- Eclipse上で、Groovyクラス/スクリプトのコンパイル/実行
- Groovyファイルのアウトラインビュー
- 自動補完
- リファクタリング
- ソースコードフォーマット
- 基本的なデバッグサポート
- Groovy コンパイラ 1.7/1.8のサポート
そういや、Groovy-Eclipseプラグインの設定については、以前こんなのも書いてました。
リファクタリング
多分Eclipse JDTの最も優れている機能の一つであるリファクタリングのサポート。さすがにJDTほどではないですが、Groovyプラグインもちょいちょいサポートしています。
機能的には、
- ローカル変数/メソッド/クラス/フィールドのリネーム
- メソッド/ローカル変数/定数に抽出
- スーパークラスにプルアップ/サブクラスにプッシュダウン
といった、まだまだ基本的な機能ばかり。
ただ、Ctrl+1(cmd+1)のquick fixがあまりサポートされてないのがちょっと残念。使う頻度の高いであろう変数名のリネームもquick fixではサポートされてなく、"コンテキストメニュー > Refactor > Rename"のように遷移しなければなりません*1。
Java<=>Groovy間でのリファクタリング
で、機能面が若干不足していることはとりあえず脇に置いておいて。
少し前にテストをプロダクトコードと別言語で書くことに関するTL - Togetterが話題になりました。(Javaに関しての)結論的な意見としては、大体↓な感じかなと。
ですが、Groovy EclipseならJava<=>Groovyの2言語間でリファクタリングが追随されるんです*2!これで、テストコードは気軽にGroovyで書きつつプロダクトコードはJavaで書いても、どちらでリファクタリングしてもちゃんと整合性が取れます。やったねたえちゃん!
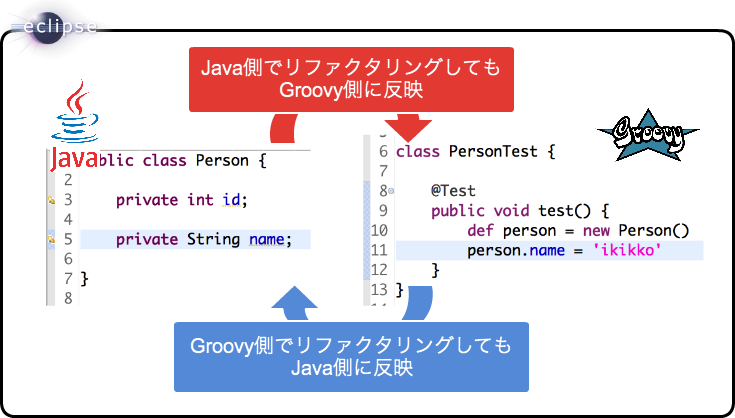
ちなみに、他のIDEは試してません キリッ。まあ、Groovyサポートが手厚いIntelliJとかなら、この辺よろしくやってくれるんじゃないかなと勝手に思っています。
それでは、みなさんよいGroovyライフを!
Groovy Eclipseを使う際にやっておいた方がいい設定
「Eclipseがいないと何にも書けないわけじゃないと〜♪」今日もまっきーを聞きながらEclipseを開いているikikkoです、こんばんは。まっきーいいですよね、まっきー。「どうしようもない僕に天使が降りてきた」とかも好きです、あの歌詞が。
@Ryuzee @ikikko インタフェースでDIをかけたけど、クラスのありかがわからない
2009-12-06 14:36:57 via web to @ryuzee
もうjavaなんて嫌いなんて言わないよ絶対

- アーティスト: 槇原敬之
- 出版社/メーカー: ダブリューイーエー・ジャパン
- 発売日: 1992/05/25
- メディア: CD
- クリック: 7回
- この商品を含むブログ (26件) を見る
普段は大体Javaメインで大体Eclipse上でコード書いているのですが、ちょこちょこやっているGroovyもEclipse上で触っています。で、EclipseにはGroovyプラグインであるGroovy - Eclipse Pluginがあるのですが、いくつかやっておいた方がいい設定があるので、簡単にご紹介。Groovy Eclipseのバージョンは、2.5.1です。
なお、あまりIDEを使ったことがない&こだわりがない人は、Groovyを書くならばIntelliJ IDEAをオススメします。
Groovy 1.8を指定する
- [Groovy > Compiler > Groovy Compiler settings]
最新入れたら、デフォルトでなってるかも。じゃなければ、SNAPSHOTのUpdate Siteから持ってくる必要があります。詳しくは、Compiler Switching within Groovy-Eclipse - Groovy - Codehausを参照してください。
ソースディレクトリ以外のGroovyファイルをコンパイルさせない
- [Groovy > Compiler > Groovy Script Folders]
(ConfigSlurper用の設定ファイル"config.groovy"などの).groovyファイルをsrc/main/resources以下に配置する場合にはこれが必要。設定しておかないと、勝手にコンパイルされてconfig.classとして扱われてしまって、Class#getResource('/config.groovy')が見つからずに失敗します。
ConfigSlurperについては、GroovyのConfigSlurperがめっちゃ便利 - No Programming, No Lifeが参考になります。

クラウド上でSeleniumスクリプトを走らせることができる、SourceLabsをGebで試してみたよ
確かJenkinsの生みの親が語る、継続的インテグレーションの未来 − @ITで出てきたSauceLabsというのが気になったので、ちょっと試してみました。
ちなみに、クラウドと言ったらもちろんコレですよね。

概要
SauceLabsとは
Cross browser testing with Selenium - Sauce Labsは、クラウド上でSeleniumテストケースを実行することができるものです。自動でスクリーンショットやビデオを撮る機能があり、いわゆるSelenium 1はもちろんSelenium 2(WebDriver)も対応しています。200分/1ヶ月の無料枠やGithubアカウントでのログインもあり、チュートリアルも結構豊富なので、試すだけならすぐに試すことができます。
ちなみに、似たようなサービスとして"CloudTesting"というものもあります。残念ながらこちらはプログラマブルなSelenium RCは対応してなく、Selenium IDEで出力されるHTML形式のテストケースしか実行できないようですが。
SauceLabsにはいくつかの機能が提供されています。
実践
今回作成したソースコードは、Github上に置いてます。
また、テスト結果はこちらのリンクに記録されています。スクリーンショットやビデオ、Seleniumの実行結果がこちらから参照できます。
前準備
ここでは、GebTestもしくはGetReportingTestを継承して、テストケースを作成する前提とします。
まず、SauceLabsのサーバを指定したDriverを作成します。createDriver()をオーバーライドして、username/accessKeyを指定したDriverを作ります。
final def USERNAME = 'XXXXXXXX' final def ACCESS_KEY = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' @Override WebDriver createDriver() { def dc = new DesiredCapabilities([ browserName: 'firefox', version: '3.6.', platform: Platform.WINDOWS, username: USERNAME, accessKey: ACCESS_KEY, name: "Hello, Sauce OnDemand with Geb!", ]) new RemoteWebDriver(new URL('http://ondemand.saucelabs.com:80/wd/hub'), dc) }
続いて、テストを実行した後に接続を切断するための処理を入れておきます。これをしておかないと(GebTestデフォルトのままだと)、SauceLabs側でテストが終了とみなされず、SauceLabsを利用出来る時間がどんどん消費されていくので、必ずやっておきましょう。
なお、@Afterアノテーションだとサブクラス側のメソッドが先に呼ばれてその後にスーパークラスの@afterメソッドが呼ばれるのですが、スーパークラス側ではすでに切断された状態で処理しようとするため、NullPointerExceptionが発生します。なので、ちょっとカッコ悪いですが、スーパークラスの@afterメソッドをオーバーライドして、先にスーパークラスの処理を行ってからdriver.quit()しています*1。
@Override void clearBrowserCookies() { super.clearBrowserCookies() browser.driver.quit() }
テストコード作成
ここでは、BacklogというBTSで「ログイン -> ダッシュボード -> プロジェクト」に遷移するだけの簡単なGebテストを実行してみます。
@Test void "ログインして1番目のプロジェクトの最新課題にコメントする"() { // ログインページ to LoginPage assert at(LoginPage) userId = 'demo' password = 'demo' submit.click() // ダッシュボードページ waitFor { at(DashboardPage) } firstProject.click() // プロジェクトページ waitFor { at(ProjectPage) } }
これで、SauceLabs側でGeb(Selenium)が走ります。上記のリンクで示したところから、スクリーンショットやビデオ、Seleniumの実行結果がを参照できます。一応、リンクをも一度ぺたり。
感想
スクリプトの作りが悪いのかもしれないけど、ちょっと いやかなり重かったです。ほんとは、「課題にコメントする」というのも実装しているのですが、SauceLabs上でテストしても遅くて高々画面4,5遷移しかしないのに多分5分以上レスポンスが全然返ってきませんでした。ローカルで走らせたときはまだそこまで時間がかからなかった30秒ぐらいで終わったんですけどねー。特にそういうドキュメントは見当たりませんでしたが、有料だとこの辺緩和されるのかな?とかも思ったり。
(自分にとっては)すぐさま実用的なものとはならないと思いますが、SeleniumやGebの復習ができたのでよしとします。
*1:Spock+Gebだとこの手法が使えなかったので断念しました。GebSpecの@afterをオーバーライドしようとすると、Spock側で「そんなことやっちゃだめよ、Specificationのfixtureを使えよハゲ」と怒られるのです。
GroovyからBacklog API(XML-RPC)を叩いてみる
J選抜でのカズのゴール&カズダンスに感動して、息子のミドルネームに「キングカズ」と名付けられないかと考えているikikkoです。こんにちは。あのゴールシーンを見ていない方は、↓から御覧ください。そのうち、日本国民としての教養として小学校の教科書にも入るんじゃないでしょうか。
背景
なんですが、XML-RPCと(Javaのような)静的型付けはあまり相性がよくないんです*1。特に、仕様上
というわけで、いつもどおりGroovyからBacklog APIを叩いてみました。
Groovy
定義が必要なライブラリはとりあえず2つ。GMavenを使ったので、POM形式です。groovy-xmlrpcにsmackが依存定義されているのですが、POMに定義されているバージョンがセントラルリポジトリに入っていないので、明示的に追加しています。
<dependency> <groupId>org.codehaus.groovy</groupId> <artifactId>groovy-xmlrpc</artifactId> <version>0.7</version> </dependency> <dependency> <groupId>jivesoftware</groupId> <artifactId>smack</artifactId> <version>3.1.0</version> </dependency>
実際のコードは↓な感じですね。
static def SPACE = 'demo' static def USER_ID = 'demo' static def PASSWORD = 'demo' static def PROJECT = 'STWK' def proxy @Before void setUp() { proxy = new XMLRPCServerProxy("https://${SPACE}.backlog.jp/XML-RPC") proxy.setBasicAuth(USER_ID, PASSWORD) } @Test public void getProjects() { proxy.backlog.getProjects().each{ println it } } @Test public void createIssue() { def project = proxy.backlog.getProject(PROJECT) def issue = proxy.backlog.createIssue([ projectId: project.id, summary: 'groovy xml-rpc test' ]) println "${issue.key} : ${issue.url}" }
Java
ちなみに、JavaでcreateIssue()をやろうとすると、こんな感じ。JavaのXML-RPCライブラリはApache XML-RPCがあります。冒頭でちょっと触れたけど、これがあまりイケテナイ。リクエスト・レスポンスともパラメータをMapやObject型で扱うので、いちいちキャストとかが必要なんですよね。コードをみたときに、本質的な処理が分かりづらい。
Map<String, Object> request = new HashMap<String, Object>(); request.put("projectId", "project.getId()"); request.put("summary", "java xml-rpc test"); Object params = new Object[] { request }; Object issue = client.execute("backlog.createIssue", params); String key = ((Map<String, Object>) issue).get("key"); String url = ((Map<String, Object>) issue).get("url"); System.out.println(key + " : " + url);
ちなみにちなみに、AtlassianからもXML-RPCライブラリが出てます。ちょっと試しただけですが、Apacheのやつよりは筋がよさそうです。
その他
ちなみにちなみにちなみに、PythonはPython から Backlog API を使う - hashimoto.py - fukuoka.pyのはてなグループな感じ。XML-RPC関連のライブラリは標準で含まれているので、別途ライブラリを導入する必要はありません。
他はあまり詳しく調べてないけど、ちょっとぐぐったら先人の人たちが色々試してくれているでしょう、たぶん。
単純にXML-RPCを叩くだけなら、動的型付けな言語だとどれもあまり変わらなそう。というか、むしろ標準ライブラリとして用意されている分、PythonとかRubyとかの方が手軽かも。ただ、自分の最近のテーマである「Java開発環境の補完」という点で考えると、やっぱりGroovyになるのかな。見て分かる通り、今回のサンプルはJUnit形式なのでJava開発時にそのままユニットテストに組み込みますしね。
*1:サンプルコードやこのエントリを書いてて、特に実感しました
Groovy-Eclipse compilerプラグインで、Maven上でGroovy!
妹の家に泊まってたら、妹が牡蠣にあたって看病することになったikikkoです。こんばんは。
EclipseでのGroovyエディタ、Groovy-Eclipseのサイトを見ていたらGroovy - Groovy-Eclipse compiler plugin for Mavenを見つけたので、ちょっと試してみました。
なお「Eclipse」とありますが、一部を除いてEclipseに特化しているわけではありません。
背景
自分の主フィールドはJava(+Maven+Eclipse)なんですが、最近はJavaが面倒なところをGroovyで補完できたらなーと考えてます。で、その一環として、テストコードをGroovyで書けないかなと調べてたところでした。プロダクトコード(src/main/~)にGroovyを突っ込むのはちょっと時期尚早な香りがするので、まずはテストコード(src/test/~)などに採用して感触を掴みたいなと。
一部ではこんなことも言われてますが、キニシナイ。。。

MavenでGroovyファイルを実行するには、何通りかやり方があるみたいですね。例えば、
- maven-antrun-pluginでGroovyコマンドを呼び出す
- http://docs.codehaus.org/display/GROOVY/Compiling+With+Maven2
- ちょっとナイーブ過ぎ…。一部のプロジェクトでスポット的にやるのならともかく、全プロジェクトで共通に使用しそうな設定はさすがにmaven-antrun-pluginはやりたくない
- GMaven
- http://docs.codehaus.org/display/GMAVEN/Home
- 経験者が語るには、ハマりどころが多い?ちょっと設定して試しただけなので、まだよくわからない*1。
でちょっと調べていたら、冒頭のようにGroovy-Eclipseのサイトで↓のようなのを見つけました。「EclipseのGroovyエディタ内で使われているGroovyコンパイラを、Mavenから呼べるようにしたもの」らしいですね。
特徴
Groovy-Eclipse compilerプラグインで、いくつか挙げられている特徴。まずはメリットから。
- Javaのスタブファイルを作らないので、スタブ関連の問題が起きない
- GMavenだとスタブファイルを作って、それに対してビルドをかける
- Eclipseエディタで使用されているものと同じコンパイラなので、EclipseとMavenでのビルドに差異が起きにくい
- 枯れているmaven-compiler-pluginを使用している
- 設定 > ビルド定義で後述してます
続いて、欠点。
- 現状、Groovy 1.7.5のみのサポート
- スタブが作られないので、Groovydoc(Javadoc)も作られない
- Groovy Mojoがサポートされない
- 具体的にどういうデメリットになるかはちょっと分かってません。すいません。。。
あと注意点として、Groovyファイルが一つもないとJavaファイルもコンパイルされません。プロダクトコード側にはGroovyファイルは必要ないってときにも、ダミーのファイルを置いてやる必要があるみたいですね。テストにのみ使用したいという自分の状況だと、これちょっとやるせないな。
設定
以下の説明を含んだ全ての設定は、Github上にあげています。
リポジトリの追加
repository / pluginRepositoryに追加します。URLを見て分かる通り、まだSNAPSHOTバージョンですね。
<repositories> <repository> <id>springsource</id> <releases><enabled>true</enabled></releases> <snapshots><enabled>true</enabled></snapshots> <url>http://maven.springframework.org/snapshot</url> </repository> </repositories> <pluginRepositories> <pluginRepository> <id>springsource</id> <url>http://maven.springframework.org/snapshot</url> </pluginRepository> </pluginRepositories>
ビルド定義
まず、maven-compiler-pluginの設定で、デフォルトのJavaコンパイラからGroovyエディタで使用しているコンパイラに変更します。ちなみに、
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>2.3.2</version> <configuration> <compilerId>groovy-eclipse-compiler</compilerId> <verbose>true</verbose> </configuration> <dependencies> <dependency> <groupId>org.codehaus.groovy</groupId> <artifactId>groovy-eclipse-compiler</artifactId> <version>0.5.1-SNAPSHOT</version> </dependency> </dependencies> </plugin>
続いて、Eclipse上にインポートしたときにGroovy natureを付ける設定。もちろん、Eclipseを使わない人は必要ありません。
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-eclipse-plugin</artifactId> <version>2.8</version> <configuration> <additionalProjectnatures> <additionalProjectnature>org.eclipse.jdt.groovy.core.groovyNature</additionalProjectnature> </additionalProjectnatures> </configuration> </plugin>
最後に、src/main/groovyとsrc/test/groovyという、groovy用のソースフォルダを定義します。公式ドキュメントとはちょっと変えて、src/test/groovyはtest用のパスに通すように。
<plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>build-helper-maven-plugin</artifactId> <version>1.5</version> <executions> <execution> <id>add-source</id> <phase>generate-sources</phase> <goals> <goal>add-source</goal> </goals> <configuration> <sources> <source>src/main/groovy</source> </sources> </configuration> </execution> <execution> <id>add-test-source</id> <phase>generate-sources</phase> <goals> <goal>add-test-source</goal> </goals> <configuration> <sources> <source>src/test/groovy</source> </sources> </configuration> </execution> </executions> </plugin>
依存性管理
Groovyを使うので、Groovyを依存ライブラリに追加。
<dependencies> <dependency> <groupId>org.codehaus.groovy</groupId> <artifactId>groovy-all</artifactId> <version>1.7.10</version> </dependency> </dependencies>
感想
まだスナップショット版ということもあって、これを全面採用は難しいでしょうね。ただ、Groovy-Eclipseエディタは頻繁にバージョンアップしてるので、あまりメンテナンスされてないように見えるGMavenより将来性という点では期待できる・・・かも。
実は、Groovyを読み書きするのはIntelliJ IDEAでやるつもりだったのです。で、Groovyだけ読み書きするのであればIntelliJでいいのですが、今回のように一部Java・一部Groovyの構成だとちょっと面倒。自分にとっては、Java開発はやっぱりEclipseが一番慣れているので。
Groovy-Eclipseエディタもどんどん改良されてるし、やっぱりEclipse一本で通したほうがいいのかな。以前は型推論が確か効かなかったような気がするのですが、今は大体できてるし(クロージャの中はちょっと怪しいけど)。型推論とCtrl+1のクイックフィックスがJDT並にできるようになると、嬉しいんですけどね。